Congratulations to PhD students Jiahao Zhang and Zifan He supervised by Professor Jason Cong for winning the Adaptive Computing category of the 2025 AMD Open Hardware competition with their project “FPGA-Optimized Large Language Model Inference: High-Speed and Accurate Design with SpinQuant.” This work utilizes the FlexLLM framework, a composable High-Level Synthesis (HLS) library for rapidly building FPGA-based LLM accelerators with hybrid temporal–spatial dataflow and state-of-the-art hardware-efficient quantization. Based on FlexLLM, the team implemented a complete inference system for the Llama-3.2 1B model in under two months with fewer than 1,000 lines of code, achieving a stage-specialized accelerator whose high-accuracy quantization surpasses the SpinQuant baseline and delivers up to 4.71× end-to-end speedup and 4.13× energy-efficiency gains over an NVIDIA A100 GPU. Their design also integrates a Hierarchical Memory Transformer (HMT) plug-in that drastically reduces prefill latency and extends the effective context window, enabling efficient long-context LLM inference on AMD FPGAs. This recognition highlights their impactful contributions at the intersection of algorithm design, quantization, and domain-specific acceleration for large language models. A demo (https://youtu.be/6VsRv5FKEsg) of this work was showcased at the annual PRISM Center Review.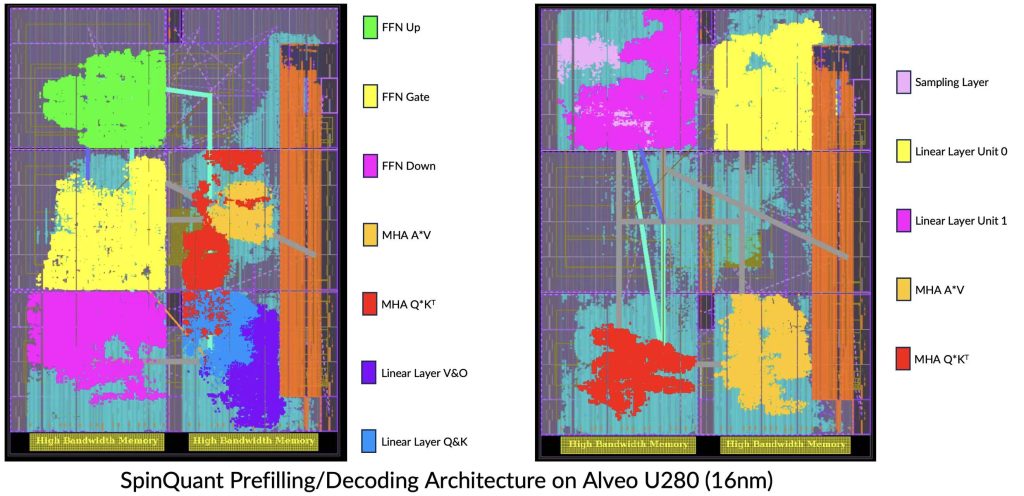
Center for Domain-Specific Computing
