
Goal:
Develop a framework to model applications and map them to heterogeneous hardware made of multi-core CPUs, GPUs, FPGAs and customized accelerators (CHP). This includes:
- The development of a two-level programming model, by decomposing the applications into atomic tasks that are orchestrated using a macro-dataflow language.
- The design and implementation of a series of compiler analysis and transformations for each hardware target, leveraging domain-specific and target-specific information.
- The design and implementation of a pattern-specific language (PSL) dedicated to stencil computations that occur in medical imaging. This PSL can be embedded in programs written in a general-purpose language such as C/C++ or Matlab.
- The development of an adaptive runtime supporting execution across heterogeneous targets, capable of work-stealing, to execute the application.
People
- Thrust Leader: Vivek Sarkar (Rice)
- Faculty: Tim Cheng (UCSB), Jens Palsberg (UCLA), Louis-Noel Pouchet (UCLA/OSU), Atanas Rountev (OSU), P. Sadayappan (OSU)
- Postdoc/Research Staff: Zoran Budimlic, Vincent Cave, Jun Shirako (Rice)
- Students:
- OSU: Tom Henretty, Justin Holewinski, Martin Kong, Naser Sedaghati, Kevin Stock
- UCLA: Mahdi Eslamimehr, Johnathan K. Lee, Moshen Lesani
- Rice: Max Grossman, Deepak Majesti, Alina Sbirlea, Dragos Sbirlea
- UCSB: Yi-Chu Wang
Focused Areas:
Domain-Specific Modeling, CHP Mapping, Embedded Domain-Specific Language for Stencil Computations, Analysis and Optimization Frameworks, Unified Adaptive Runtime System for Heterogeneous Scheduling
We define executable models using a Graph Representation (CDSC-GR), and enable each step in the graph to be written either in any native programming language by the user, or by using embedded Domain-Specific Languages (eDSLs) within a general-purpose programming language. eDSLs capture common computing patterns that occur in the application domain, such as stencil computations, and are the target of advanced automatic optimizations for best performance.
Overview
CDSC-GR is a dataflow intermediate graph representation (DFGR) derived from ideas in Intel’s Concurrent Collections (CnC) and Habanero-C programming models. CDSC-GR steps can be written in a variety of sequential and parallel languages – C, C++, Fortran, Python, Java, Scala, Matlab, Habanero-C (HC), Habanero-Java. Figure 1 illustrates the modeling of a medical imaging pipeline (left) into data and control dependences (top).
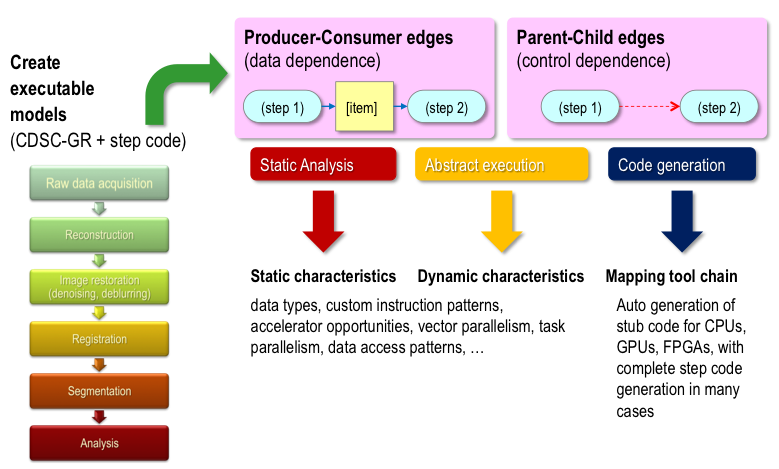
Figure 1: Application modeling using DFGR
From a mathematical specification to a graph representation
Figure 2 shows the mathematical specification of a compressive sensing MRI algorithm (left), as expressed by domain experts. On the right, its graph representation is shown, where dataflow relationships are represented between steps, in red. Data is shown using blue boxes. Multiple instances of each step is performed, until the convergence condition is met. Step instances are uniquely identified by a tag (not shown in this graph). Task, data, and pipeline parallelism are all expressed within a single representation.

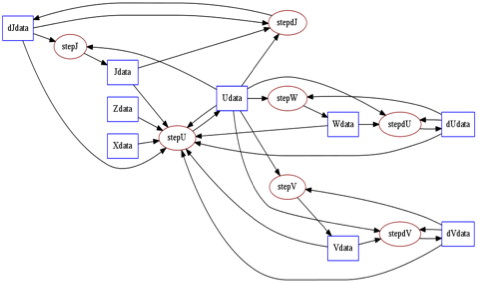
Figure 2: Compressive sensing MRI: graph modeling
Analyzing and optimizing the DFGR graph representation
The DFGR graph may be analyzed to extract essential information such as the “liveness” of items (i.e., how many times an item will be read) and whether dependences allow to coarsen the tasks into larger atomic tasks, akin to tiling the representation. For the subset of DFGR graphs that are expressed using only simple affine relationships between tags, the program can be optimized using the polyhedral compilation framework. We illustrate this in Figure 3, using the Smith-Waterman dynamic programming algorithm. It is a central method to determine sequence alignment, and is (or variants of it) used in numerous genetics software. On the left, an equivalent sequential C code is shown, and in the middle its DFGR graph representation is shown. It is a textual representation of the graph, where tag functions (e.g., “i,j-1” in [A:i,j-1]) are used to relate which data items are read/written by which instance of a step. In this case, functions top(), left(), and center() perform very few computations and the runtime overhead of handling these fine-grained tasks is high. To improve performance for instance on multi-core CPUs it is desired to coarsen the granularity of tasks, leading to a new graph shown on the right. The main aspects to notice are the creation of different steps renamed to “newStmtXX”, and the skewed dependence introduced to ensure coarsened steps are still atomic, a requirement in DFGR.



Figure 3: DFGR coarsening for Smith-Waterman
DFGR has been purportedly designed with concepts from polyhedral representation and optimization in mind, to allow for graph transformations using the polyhedral model when possible. Step coarsening in DFGR is in essence classical polyhedral tiling on the polyhedral representation we extracted. Tiling achieves the coarsening and data locality objective, and as importantly, ensures by definition that tiles are atomic execution units. DFGR requires step instances to be atomic, therefore coarsening via tiling is an effective way to preserve DFGR semantics. We implemented step coarsening by using the Pluto transformation algorithm implementing the Tiling Hyperplane method. This model-driven scheduler finds a transformation so that (1) data locality is maximized; (2) tilability is maximized, all under the framework restrictions of course.
From a graph representation to a parallel program
A DFGR graph can be translated to a variety of task-parallel languages. At CDSC we developed translators to the Habanero-C language, for execution using the HC runtime. Figure 4 illustrates this translation. An essential aspect is that the functions implementing the step bodies are “black boxes” to this translator: the translator only needs to be able to call these functions providing the tag value and the items to be read/written. The user (or another compiler) is in charge of providing target-specific implementation of steps, and one can provide a step implementation for GPUs, another one for CPUs, etc. The runtime may then decide, depending on the current resource usage for instance, which target to use to execute a step instance, and the appropriate step body implementation (if provided) is automatically called.
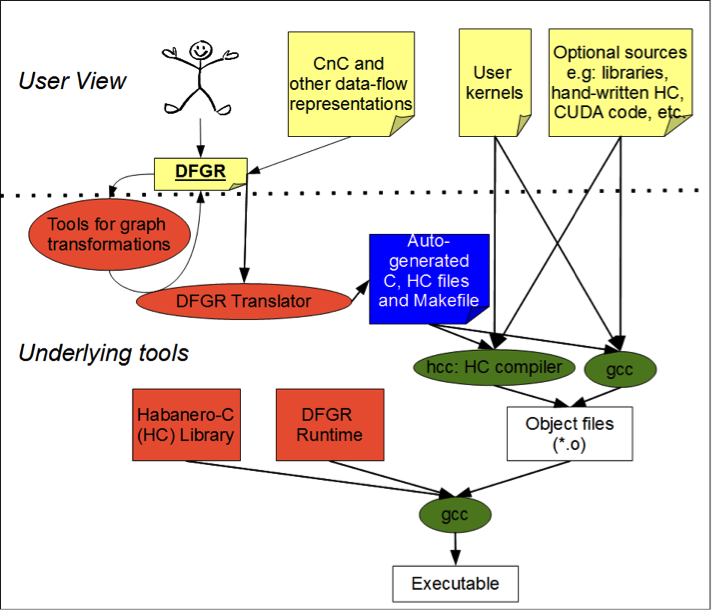
Figure 4: DFGR translation
We have selected below some of our publications on the foundations of modeling applications using Concurrent Collections and its derivative:
- [CR10B] Zoran Budimlic, Michael Burke, Vincent Cave, Kathleen Knobe, Geoff Lowney, Ryan Newton, Jens Palsberg, David Peixotto, Vivek Sarkar, Frank Schlimbach, Sagnak Tasirlar. “Concurrent Collections”, Scientific Programming, 18:3-4, pp. 203-217, August 201
- [CAP10B] Zoran Budimlic, Alex Bui, Jason Cong, Glenn Reinman, Vivek Sarkar, “Modeling and Mapping for Customizable Domain-Specific Computing”, Workshop on Concurrency for the Application Programmer (CAP), co-located with SPLASH 2010, October 2010.
- [DFM13S] Dragoș Sbîrlea, Alina Sbîrlea, Kyle B. Wheeler, Vivek Sarkar, The Flexible Preconditions Model for Macro-Dataflow Execution, the 3rd Data-Flow Execution Models for Extreme Scale Computing (DFM), September 2013.
- [DFM14S] Alina Sbirlea, Louis-Noel Pouchet, Vivek Sarkar. DFGR: an Intermediate Graph Representation for Macro-Dataflow Programs. Fourth Workshop on Dataflow Execution Models for Extreme Scale Computing – in conjunction with PACT 2014.
A key aspect of our mapping strategy is to use CDSC-GR to bridge from executable models to deployable code. CDSC-GR remains unchanged from modeling to CHP mapping stage: we implement a write-once-customize-everywhere (WOCA) strategy. The step codes need to be migrated to Habanero-C/OpenMP for CPU cores, OpenCL for GPU cores, and hardware synthesis for FPGAs. We developed automated multi-target code generation for steps written in a domain-specific language (eSDSL).
To map deployable codes on to CHP that are modeled using the CDSC-GR language, we resort to source-to-source mapper for Habanero-C based on ROSE compiler, optimizing back-end based on LLVM (with translator from ROSE IR to LLVM IR). Individual steps are further optimized using the CDSC Mapper infrastructure, as shown below. Finally, we use a unified adaptive runtime system for task scheduling, data movement, and synchronization across heterogeneous CHP processors.
Mapping Infrastructure
The CDSC Mapper is a compiler package for heterogeneous mapping on various targets such as multi-core CPUs, GPUs and FPGAs. The objective is to provide the user with a complete compilation platform to ease the programming of complex heterogeneous devices, such as a Convey HC1-ex machine. The architecture of the compiler is based on a collection of production-quality compilers such as GNU GCC, Nvidia CC and LLVM; one open-source compilation infrastructures on top of which development has been performed: the LLNL ROSE compiler; and a collection of research compilers and runtime such as CnC-HC, PolyOpt and SDSLc.
Some of the fundamental features of this software infrastructure include: (1) the use of a two-level programming model, where an application is decomposed into computation steps which can be implemented in any language (C, CUDA, etc.), and the orchestration of these steps is modeled using a dataflow language (either Intel CnC or CDSC- GR, a language we developed). (2) The use of an asynchronous parallel language, Habanero-C, to implement the inter-step parallelism. It is associated with a dynamic run-time capable of work stealing between heterogeneous targets such as CPUs, GPUs and FPGAs inside the same system. (3) The use of a domain-specific language that can be embedded in a native language such as C/C++ or Matlab to represent the segments of the computation which use a stencil pattern. We provide target-specific compilers for this DSL, to CPUs, GPUs and FPGAs ensuring performance portability from a single input source. (4) The use of advanced polyhedral compilation algorithms to transform the computation steps (in DSL, C, C++ or Fortran) performing automatic parallelization, tiling and vectorization for CPU and FPGA execution. An overview is provided in Figure 5.
The objective of the CDSC Mapper is to simplify the development of applications on heterogeneous devices. To achieve this goal, we use a multi-layer programming principle:
- The application is decomposed into steps, which can be executed atomically on a given device. These steps can be implemented in a variety of sequential and parallel languages, such as C, C++, CUDA, or Habanero-C.
- The coordination (control and data flow) between these steps is described through a dataflow language, us- ing either Intel Concurrent Collections or CDSC-GR, which is automatically translated into the Habanero-C parallel language to exploit a dynamic heterogeneous run-time system for parallel step execution.
- Furthermore inside each step implementation, a domain-specific language (Stencil-DSL) is used to represent some compute-intensive part of the application. Target-specific compilers for this DSL are used to create highly-efficient execution of these program parts.
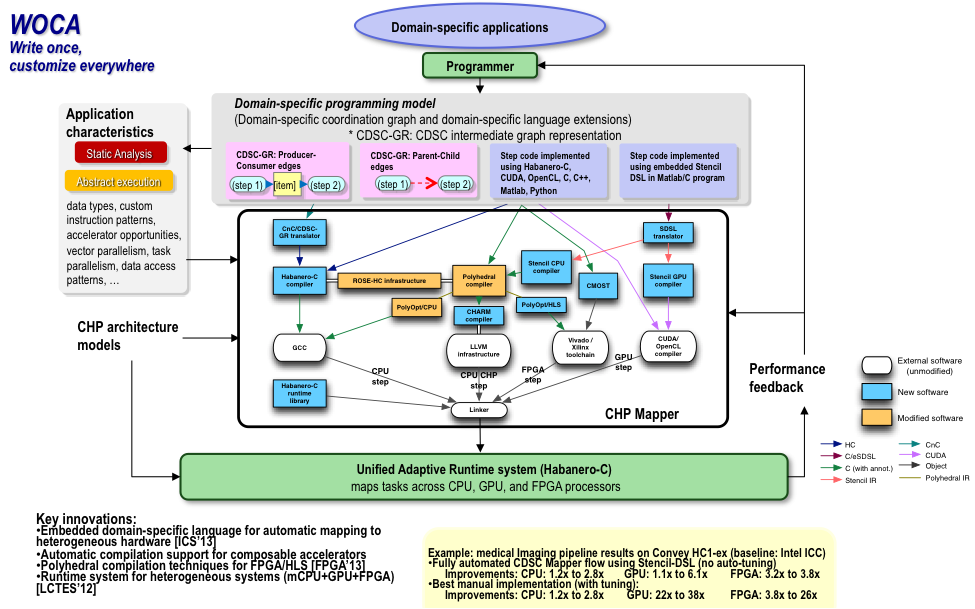
Figure 5: Overview of CDSC Mapper
The CDSC Mapper is currently in its second beta release, and many features are still at experimental stages. Please provide feedback, bug reports and improvement suggestions at cdsc-mapper-users@cdsc.ucla.edu Louis-Noel Pouchet pouchet@cs.ucla.edu is the current maintainer of the CDSC Mapper.
The CDSC Mapper package is available for download at http://cdsc.ucla.edu. An extensive documentation about how to install the mapper is available in the doc/ directory, or directly on the download page. A complete end-to-end example containing a 3D imaging pipeline is also available for download. The CDSC Mapper is released under a standard 3-clause BSD license. The license can be found in the LICENSE.txt file. The CDSC Mapper installs several third-party software components that are licensed either under BSD terms, GPL terms or LGPL terms.
Embedded Domain-Specific Language for Stencil Computations
Embedded Domain-Specific Language for Multi-Target Code Generation
There are multiple benefits of using a high-level specification of computations using domain-specific languages. First, from a programmability/productivity point of view, DSLs improve the ease of use especially for the mathematicians/scientists creating the code. It allows them to focus exclusively on the semantics, without considerations about the particular implementation to be used for high-performance execution on a particular target. At the other end, DSLs are usually simplified languages that significantly ease the design and implementation of compiler optimizations. It facilitates loop and data transformations application that are needed for each individual target. We have created a series of pattern-specific-target-specific compilers, each taking as input the exact same input program description using the SDSL syntax. The compilers then take care of implementing the various program transformations needed for each specific target (time-tiling and SIMD vectorization for CPUs, overlapped tiling for GPUs to avoid uncoalesced accesses, on-chip data reuse optimizations for FPGAs, etc.). Figure 6 shows an overview of the SDSL compiler we designed.
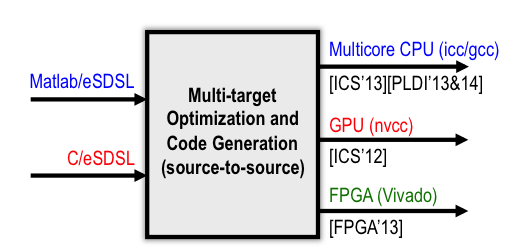
Figure 6: SDSL compiler overview
Embedded DSLs provide additional flexibility: indeed instead of offering a full-flavored language, thereby making it more complex to allow the programmers to represent the full program, we instead embed a DSL region into a full-flavored general-purpose language such as C or Matlab.
Figure 7 shows an example of describing an iterative stencil (with convergence checking) in the SDSL language. Domain experts define precisely the boundary regions and conditions, as well as the mathematical computation performed on each cell. They can also propagate an essential knowledge about the numerical stability of the code with the “check xx every yy iterations”, which informs the compiler that the convergence check xx may be performed only every yy time iterations, instead of every time iterations. This in turn enables powerful optimizations such as time-tiling, significantly improving performance.
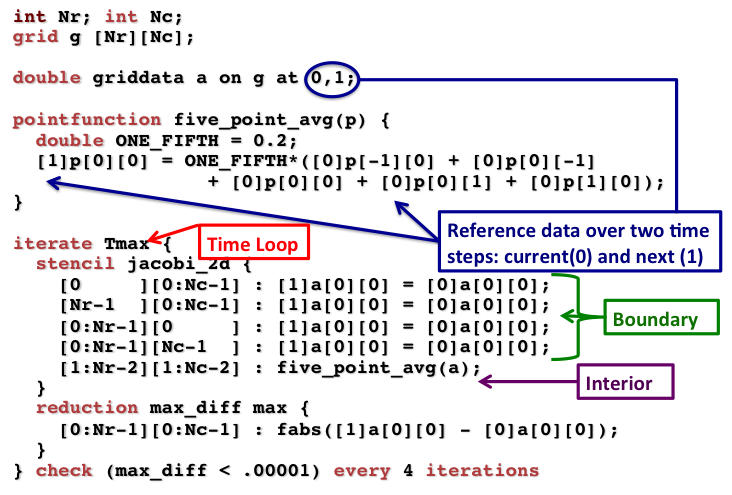
Figure 7: SDSL example
The DSL fragment represents only the compute-intensive part(s) using a stencil pattern. It allows the seamless integration of the technology into existing codes with only little efforts from the developer. For instance when integrating in a Matlab code, the performance improvement over “interpreted” Matlab or even Matlab Coder is very significant, as shown in Figure 8 for a Rician denoise computing step.
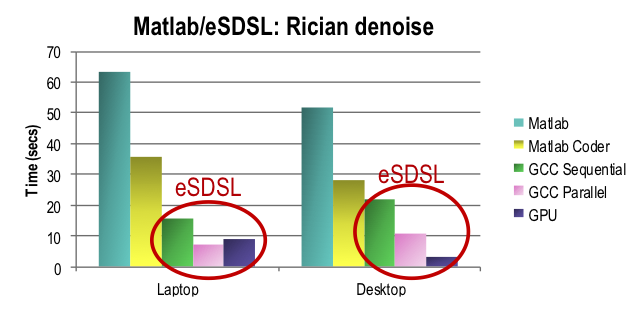
Figure 8: Performance improvement using SDSL
Target-specific code generation strategies for Stencil computations
We have developed and published a collection of high-performance code generation strategies for multi-core CPUs, GPUs, FPGAs, and CHP. We illustrate below a handful of them, relating to high-performance stencil execution on multi-core CPUs.
Vector operations with ISAs like SSE require the loading of physically contiguous data elements from memory into vector registers and the execution of identical and independent operations on the components of vector registers. Stencil computations pose challenges to efficient implementation on these architectures, requiring the use of redundant and unaligned loads of data elements from memory into different slots in different vector registers. The DLT data layout transformation of Henretty et al. was developed to overcome the fundamental data access inefficiency on current short-vector SIMD architectures with stencil computations, and is illustrated in Figure 9. It ensures vector operations on stencil can be performed without any shuffle or extra load.
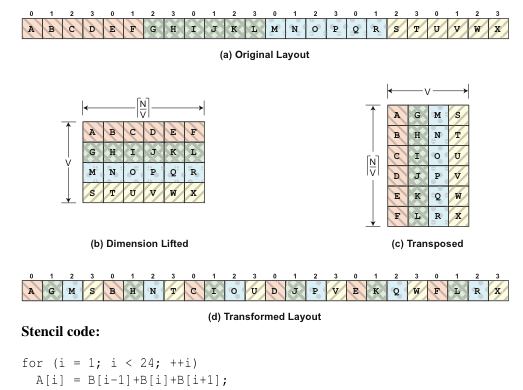
Figure 9: Dimension-Lift-and-Transpose (DLT)
But coupling DLT with time-tiling techniques poses challenges on the acceptable tile shapes and overall strategy. We have developed nested split-tiling, in which a d-dimensional loop spatial loop nest is recursively split-tiled along each dimension. The outermost spatial loop at level d is split-tiled, producing a loop over upright tiles and a loop over inverted tiles. Inside each of these loops, loop level d − 1 is split-tiled, giving four tile loop nests. Split-tiling is performed recursively in each new loop nest until the base loop level 1 is reached and there are 2d total loop nests corresponding to all possible combinations of upright and inverted tiles on each dimension. For higher dimensional problems, the constraint on upright tile size causes tiles to overflow cache for even small time tile sizes. We overcome the tile size constraints of nested split-tiling with a hybrid of standard tiling on the outermost space loops and split-tiling on the inner loops. Hybrid split-tiling for a 2D stencil as illustrated in Figure 10(b).
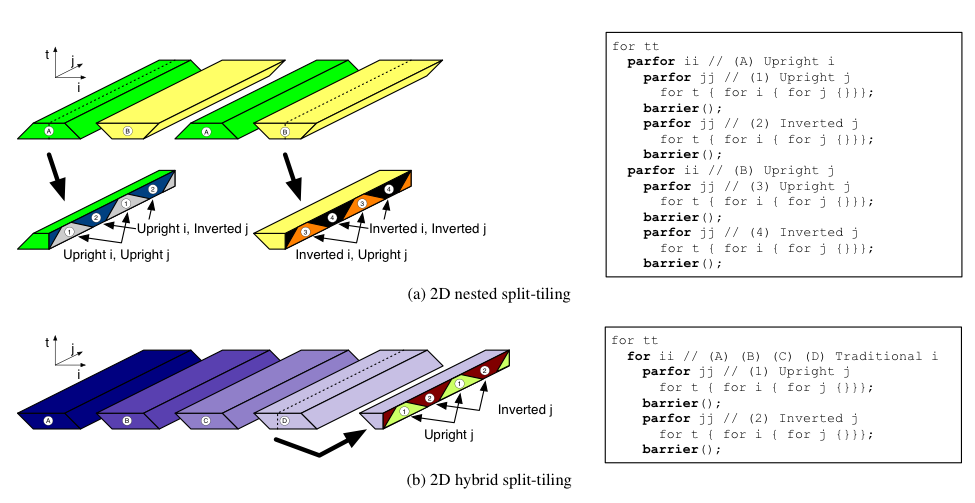
Figure 10: Nested and Hybrid split-tiling
Performance gains are very high, as shown in Figure 11 where we compare DLT+nested/hybrid split tiling against the reference compiler (ICC) and two reference optimizing compilers for stencils (Pochoir and Pluto).
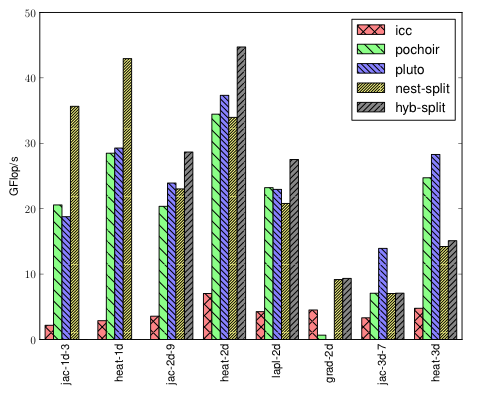
Figure 11: Performance improvement on Core i7-2600k
We have also developed a customized solution for executing high-order stencils (i.e., stencils where the neighborhood of a cell used to update its value extends beyond its immediately adjacent cells), to address the problem of excessive register pressure for such stencils. This optimization is targeted at architectures with a limited number of registers available, such as multi-core CPUs. Figure 12 illustrates different schemes to execute a stencil. Reads are shown in purple, writes in yellow. The classical way to execute a stencil is to follow the gather-gather approach, where each neighbor is read to update one cell. Instead, we propose to reorder the computation, exploiting the associativity of operations in a convolution, to trade off reads for writes. Figure 12 shows some of these alternatives, and reports the number of load/stores needed as well as the number of registers needed to implement perfect reuse.
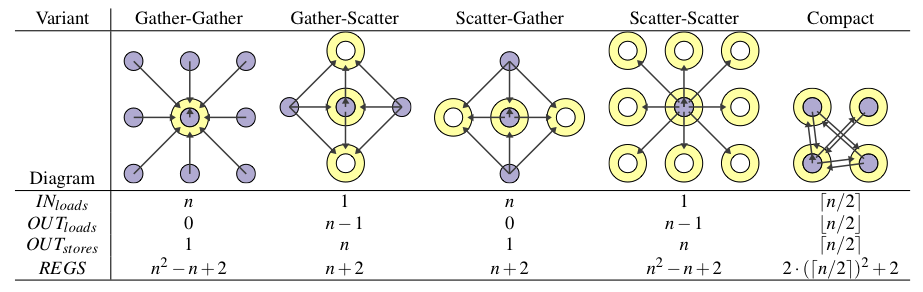
Figure 12: Various execution alternatives for a stencil
This approach provides essential performance improvements especially for high-order stencils, where register spilling is a performance problem. Figure 13 shows the performance achieved with our approach (in sequential and parallel), with and without the DLT transformation, compared to a reference baseline using Intel ICC, for a variety of 2D and 3D stencils. Our approach, especially for high-order 2D stencils, enables to essentially maintain the number of stencil per second (i.e., pixel per second) that can be processed even when increasing the stencil order and therefore its accuracy.
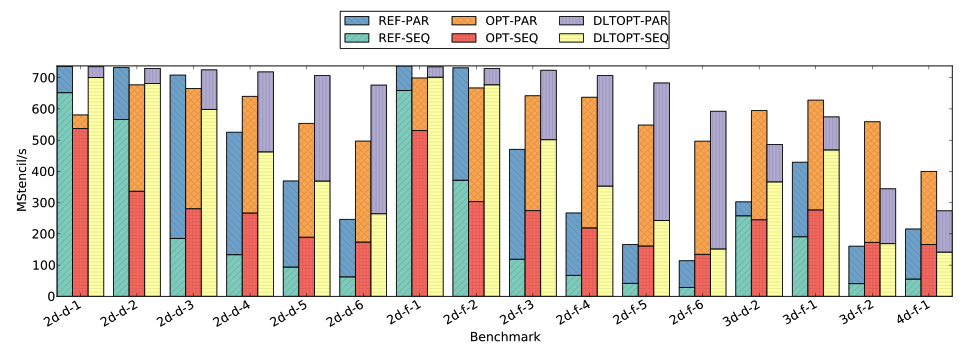
Figure 13: Performance on Intel Core i7-4770k
Some selected publications on target-specific optimization for Stencil computations include:
- [CC11H] Tom Henretty, Kevin Stock, Louis-Noel Pouchet, Franz Franchetti, J. Ramanujam and P. Sadayappan, “Data Layout Transformation for Stencil Computations on Short SIMD Architectures”, ETAPS International Conference on Compiler Construction (CC’11), Saarbrucken, Germany, Macrh 2011.
- [PACT11S] Naser Sedaghati, Louis-Noel Pouchet, Renji Thomas, Radu Teodorescu, and P. Sadayappan, “A Vector Instruction Extension for High Performance Stencil Computation,” International Conference on Parallel Architectures and Compilation Techniques (PACT 2011),
- [ICS12H] Holewinski, , L.-N. Pouchet, and P. Sadayappan. High-performance code generation for stencil computations on gpu architectures. In Proceedings of the 26th International Conference on Supercomputing, ICS ’12. ACM, 2012.
- [ICS13H] Tom Henretty, Richard Veras, Franz Franchetti, Louis-Noël Pouchet, J. Ramanujam and P. Sadayappan, “A Stencil Compiler for Short-Vector SIMD Architectures,” Proc. ACM International Conference on Supercomputing (ICS’13), Eugene, OR, June 2013.
- [PLDI14S] Kevin Stock, M. Kong, Tobias Grosser, Louis-Noel Pouchet, Fabrice Rastello, J. Ramanujam and P. Sadayappan, “A Framework for Enhancing Data Reuse via Associative Reordering,” ACM SIGPLAN conference on Programming Language Design and Implementation (PLDI), June 2014.
Analysis and Optimization Frameworks
The CDSC Mapping strategy employs advanced compiler analysis and optimizations to deliver high-performance programs. The research conducted addressed the effective mapping of general-purpose task-parallel programs, following the idioms developed in CDSC-GR, for a variety of hardware targets.
Effective Mapping of Task Parallelism
The underlying implementation of CDSC-GR graphs uses a task-parallel language to implement the concurrency, synchronization and communications required. We conducted extensive research and development around the Habanero infrastructure, used to implement CnC variants and CDSC-GR as shown above. Our research includes the development of the Habanero-C (HC) compiler and its associated toolchain, including support for Data-Driven Tasks (DDTs) to HC (DDTs were originally developed for Habanero-Java). DDTs can be used to create arbitrary task graph structures in HC, greatly simplifying the task of mapping CDSC-GR programs onto the target architecture and runtime. We designed a new approach to static may- happen-in-parallel analysis of languages with async-finish parallelism, including X10 and HC, and developed several race detection frameworks for task-parallel programs. More information can be found in the selected list of publications below:
- [PPOPP10L] Jonathan K. Lee, Jens Palsberg, “Featherweight X10: a core calculus for async-finish parallelism”, Principles and Practice of Parallel Programming (PPoPP) Conference, Bangalore, India, pp. 25-36, January 2010.
- [RV10R] Raghavan Raman, Jisheng Zhao, Vivek Sarkar, Martin Vechev, Eran Yahav, “Efficient Data Race Detection for Async-Finish Parallelism”, Proceedings of the 1st International Conference on Runtime Verification (RV ’10), November 2010.
- [ICCP11T] Data-Driven Tasks and their Implementation. Sagnak Tasirlar, Vivek Sarkar. Proceedings of the International Conference on Parallel Processing (ICPP) 2011, September 2011.
- [PLDI12R] Scalable and Precise Dynamic Data Race Detection for Structured Parallelism. Raghavan Raman, Jisheng Zhao, Vivek Sarkar, Martin Vechev, Eran Yahav. 33rd ACM SIGPLAN conference on Programming Language Design and Implementation (PLDI), June 2012
- [SAS12L] Jonathan K. Lee, Jens Palsberg, Rupak Majumdar, Hong Hong, “Efficient May Happen in Parallel Analysis for Async-Finish Parallelism”, Static Analysis Symposium 2012.
- [OOPSLA12I] Shams Imam, Vivek Sarkar. Integrating Task Parallelism with Actors. Conference on Object-Oriented Programming, Systems, Languages, and Applications (OOPSLA), October 2012.
- [PACT13B] Rajkishore Barik, Jisheng Zhao, Vivek Sarkar. Interprocedural Strength Reduction of Critical Sections in Explicitly-Parallel Programs. The 22nd International Conference on Parallel Architectures and Compilation Techniques (PACT), Edimburgh, UK, Sept. 7-11 2013.
- [TOPLAS13N] Krishna Nandivada, Jun Shirako, Jisheng Zhao, Vivek Sarkar. A Transformation Framework for Optimizing Task-Parallelism Programs. ACM Transactions on Programming Languages and Systems, Volume 35, May 2013.
- [PACT14S] Dragos Sbirlea, Zoran Budimlic, Vivek Sarkar. Bounded Memory Scheduling of Dynamic Task Graphs. International Conference on Parallel Architectures and Compilation Techniques (PACT), August 2014.
- [CAV14L] Mohsen Lesani, Todd Millstein and Jens Palsberg: Automatic Atomicity Verification for Clients of Concurrent Data Structures. CAV 2014.
- [PPOPP14E] Mahdi Eslamimehr, Jens Palsberg: Race directed scheduling of concurrent programs. PPOPP 2014: 301-314.
Multi-core CPUs
In complement to domain-specific code optimization strategies we have developed a collection of more general-purpose optimization processes to automatically transform task bodies and regular dataflow graphs targeting multi-core SIMD CPUs. In particular, we created numerous optimizations using the polyhedral compilation framework, which specializes in analyzing and transforming programs with static control-flow. We developed automatic transformations to expose the adequate balance between SIMD, coarse-grain parallelism and data locality to maximize performance of computation kernels on modern CPUs. This research is implemented in the ROSE-based PolyOpt component of the CDSC Mapper. Additional information can be found in the following publications:
- [MICRO10B] Rajkishore Barik, Jisheng Zhao, Vivek Sarkar, “Efficient Selection of Vector Instructions using Dynamic Programming”, MICRO-43, December 2010.
- [TACO12S] Stock, L.-N. Pouchet, and P. Sadayappan. Using machine learning to improve automatic vectorization. ACM Trans. Archit. Code Optim., 8(4):50:1-50:23, Jan. 2012.
- [CC12S] Analytical Bounds for Optimal Tile Size Selection. Jun Shirako, Kamal Sharma, Naznin Fauzia, Louis-Noel Pouchet, J. Ramanujam, P. Sadayappan, Vivek Sarkar. Proceedings of the 2012 International Conference on Compiler Construction (CC 2012), April 2012.
- [IJPP13P] Eunjung Park, John Cavazos, Louis-Noël Pouchet, Cédric Bastoul, Albert Cohen and P. Sadayappan, “Predictive Modeling in a Polyhedral Optimization Space,” International Journal of Parallel Programming (IJPP), Volume 41, Issue 5, pp. 704-750, 2013.
- [PLDI13K] Martin Kong, Richard Veras, Kevin Stock, Franz Franchetti, Louis-Noël Pouchet and P. Sadayappan, “When Polyhedral Transformations Meet SIMD Code Generation,” Proc. ACM SIGPLAN Conference on Programming Language Design and Implementation (PLDI’13), Seattle, WA, June 2013.
- [SC14S] Jun Shirako, Louis-Noel Pouchet, Vivek Sarkar. Oil and Water Can Mix: An Integration of Polyhydral and AST-based Transformations. IEEE Conference on High Performance Computing, Networking, Storage and Analysis (SC’14), November 2014.
GPUs
We extended the CnC model to enable prescription and execution of steps on both CPU and GPU processors. The CnC-CUDA extensions for GPUs include the definition of multithreaded steps for execution on GPUs, and automatic generation of data and control flow between CPU steps and GPU steps. Experimental results showed that this approach could yield significant performance benefits with hybrid CPU/GPU execution. Publications focusing on GPU execution include:
- [LCPC10G] Max Grossman, Alina Simion, Zoran Budimlic, Vivek Sarkar, “CnC-CUDA: Declarative Programming for GPU’s”, 2010 Workshop on Languages and Compilers for Parallel Computing (LCPC), October 2010.
- [ECVW11W] Yi-Chu Wang and K.-T. Tim Cheng, “Energy-Optimized Mapping of Application to Smartphone Platform – A Case Study of Mobile Face Recognition,” IEEE Workshop on Embedded Computer Vision (ECVW 2011, In conjunction with CVPR2011) Colorado Springs, USA, June 2011.
- [HPDIC13G] Max Grossman, Mauricio Breternitz, Vivek Sarkar. HadoopCL: MapReduce on Distributed Heterogeneous Platforms Through Seamless Integration of Hadoop and OpenCL. International Workshop on High Performance Data Intensive Computing, May 2013.
- [LCPC13H] Akihiro Hayashi, Max Grossman, Jisheng Zhao, Jun Shirako, Vivek Sarkar, Speculative Execution of Parallel Programs with Precise Exception Semantics on GPUs, the 26th International Workshop on Languages and Compilers for Parallel Computing (LCPC), September 2013.
- [PPPJ13H] Akihiro Hayashi, Max Grossman, Jisheng Zhao, Jun Shirako, Vivek Sarkar, Accelerating Habanero-Java Programs with OpenCL Generation, 10th International Conference on the Principles and Practice of Programming in Java (PPPJ), September 2013.
- [CGO15F] Naznin Fauzia, Louis-Noël Pouchet and P. Sadayappan. Characterizing and Enhancing Global Memory Data Coalescing on GPU. In IEEE/ACM 13th Symposium on Code Generation and Optimization (CGO’15), San Francisco, CA, February 2015.
Configurable Computing and FPGAs
High level synthesis (HLS) tools for synthesizing designs specified in a behavioral programming language like C/C++ can dramatically reduce the design time especially for embedded systems. While the state-of-art HLS tools have made it possible to achieve quality of results close to hand coded RTL designs from designs specified completely in C/C++, considerable manual design optimization is still often required from the designer. To get a HLS friendly C/C++ specification, the user often needs to perform a number of explicit source-code transformations addressing several key issues such as on-chip buffer management, choice of degree of parallelism/pipelining, attention to prefetching, avoidance of memory port conflicts etc., before designs rivaling hand coded RTL can be synthesized by the HLS tool. The research from CDSC aimed to overcome these issues, by providing automated solutions to dramatically improve the programming productivity for configurable computing, an essential enabler to the widespread deployment of these technologies. For example, we developed a fully automated C-to-FPGA framework to effectively implements data reuse through aggressive loop transformation-based program re-structuring. This research finds applications in FPGAs, but also in configurable heterogeneous platforms promoted by the center. Selected publications include:
- [OOPSLA10K] Stephen Kou, Jens Palsberg, “From OO to FPGA: fitting round objects into square hardware?”, Object Oriented Programming Systems and Applications Conference (OOPSLA), October 2010.
- [ASPDAC12C] Cong, M.A. Ghodrat, M. Gill, H. Huang, B. Liu, R. Prabhakar, G. Reinman and M. Vitanza, “Compilation and Architecture Support for Customized Vector Instruction”, Proceedings of the 17th Asia and South Pacific Design Automation Conference (ASPDAC 2012), Sydney, Australia, pp. 652-657, January 2012
- [DAC12C] Cong, P. Zhang and Y. Zou, “Optimizing Memory Hierarchy Allocation with Loop Transformations for High-Level Synthesis”, to appear in the Proceedings of the 49th Annual Design Automation Conference (DAC 2012), San Francisco, CA, June 2012.
- [FPGA13P] Louis-Noël Pouchet, Peng Zhang, P. Sadayappan and Jason Cong,“Polyhedral-Based Data Reuse Optimization for Configurable Computing,” Proc. 21st ACM/SIGDA International Symposium on Field-Programmable Gate Arrays (FPGA’13), Monterey, CA, February 2013.
- [CODES13Z] Zuo, P. Li, D. Chen, L-N. Pouchet, S. Zhong and J. Cong. Improving Polyhedral Code Generation for High-Level Synthesis. Proceedings of the International Conference on Hardware/Software Co-design and System Synthesis (CODES+ISSS 2013), Montreal, Canada, pp. 1-10, September-October 2013.
- [FPGA14C] Jason Cong, Muhuan Huang, Peng Zhang. Combining computation and communication optimizations in system synthesis for streaming applications. International Symposium on Field-Programmable Gate Arrays, FPGA 2014.
- [DAC14C] Jason Cong, Peng Li , Bingjun Xiao, and Peng Zhang, “An Optimal Microarchitecture for Stencil Computation Acceleration Based on Non-Uniform Partitioning of Data Reuse Buffers”, Design Automation Conference, 2014.
- [DAC15Z] Peng Zhang, Muhuan Huang, Bingjun Xiao, Hui Huang, and Jason Cong. “CMOST: A System-Level FPGA Compilation Framework,” Design Automation Conference (DAC) 2015, San Francisco, CA, June 7-11, 2015.
- [ISPASS15C] Yu-Ting Chen, Jason Cong, and Bingjun Xiao, “ARACompiler: A Prototyping Flow and Evaluation Framework for Accelerator-Rich Architectures”, 2015 IEEE International Symposium on Performance Analysis of Systems and Software (ISPASS), Philadelphia, PA, March 29-31, 2015.
Unified Adaptive Runtime System for Heterogeneous Scheduling
CDSC-GR supports a dynamic dataflow model, without requiring that an underlying sequential program be provided. Each task in a CDSC-GR program can be compiled for execution on multiple heterogeneous processors. An adaptive runtime system dynamically decides which processor should execute a given task. To the best of our knowledge, this is the first system with the above characteristics. Figure 14 illustrates the flow of operations for our adaptive runtime (left), and its performance when used on a medical imaging pipeline made of 3 steps (denoise, registration, segmentation) running on a Convey HC1-ex.
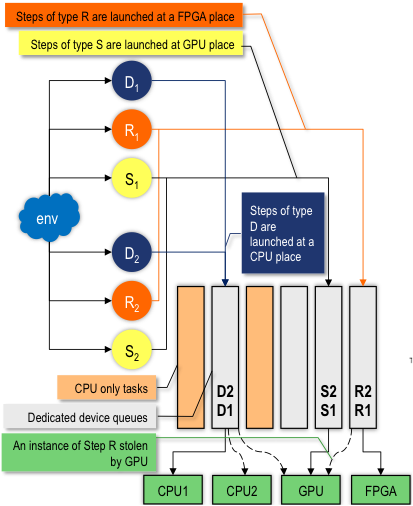
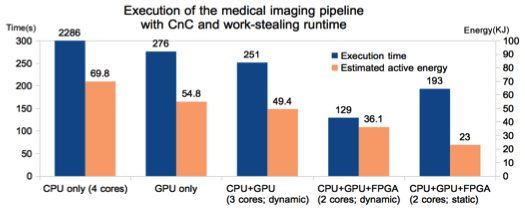
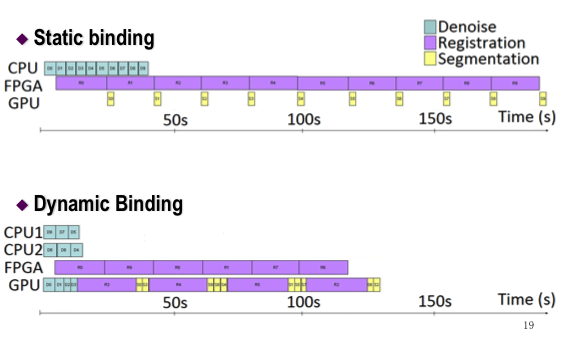
Figure 14: Adaptive heterogeneous run-time
The goal of this component is to provide a unified runtime interface for scheduling tasks across the heterogeneous processors in the CHP. Since Habanero-C serves as the integration language for CHP Mapping, the unified runtime is centered on the Habanero- C runtime system. More information can be found in:
- [LCPC11C] Dynamic Task Parallelism with a GPU Work-Stealing Runtime System. Sanjay Chatterjee, Max Grossman, Alina Sbirlea, Vivek Sarkar. 2011 Workshop on Languages and Compilers for Parallel Computing (LCPC), September 2011
- [LCTES12S] Sbirlea, Y. Zou, Z. Budimlic, J. Cong and V. Sarkar, Mapping a Data-Flow Programming Model onto Heterogeneous Platforms, Proc. ACM SIGPLAN/SIGBED Conference on. Languages, Compilers, Tools and Theory for Embedded Systems (LCTES), Beijing, China, Jun 2012
- [EUROPAR12S] Folding of Tagged Single Assignment Values for Memory-Efficient Parallelism. Dragos Sbirlea, Kathleen Knobe, Vivek Sarkar. International European Conference on Parallel and Distributed Computing (Euro-Par), August 2012.