
Goal:
Develop a framework to aid in the creation of a customizable heterogeneous platform (CHP) for a given application domain. This includes:
- Leveraging domain modeling and profiling to understand the specific needs and bottlenecks of the domain.
- Proposing innovative architectural solutions for domain-specific problems.
- Evaluating architectural designs using our in-house cycle-accurate simulation infrastructure.
People
- Thrust Leader: Glenn Reinman (UCLA)
- Faculty: Jason Cong, Frank Chang (UCLA)
- Postdoc/Research Staff: Zhenman Fang, Mohammadali Ghodrat (UCLA)
- Students: Michael Gill, Beayna Grigorian, Yuchen Hao, Hui Huang, Chunyue Liu, Chunhua Xiao, Bo Yuan (UCLA)
Focused Areas:
Simulation Infrastructure: PARADE, Accelerator-Rich CMPs (ARC), Composable Heterogeneous Accelerator-Rich Microprocessor (CHARM), Composable Accelerator-rich Microprocessor Enhanced for Adaptivity and Longevity (CAMEL), Buffer-in-NUCA (BiN), Stream Arbitration, Interconnection Networks for Accelerator-Rich Architectures
Customizable Heterogeneous Platform (CHP)
A Customizable Heterogeneous Platform (CHP) consists of a heterogeneous set of adaptive computational resources connected with high-bandwidth, low-power non-traditional reconfigurable interconnects. Specifically, a CHP may include: 1) the integration of customizable cores and accelerators or co-processors that will enable power-efficient performance tuned to the specific needs of an application domain; 2) reconfigurable high-bandwidth and low-latency on-chip and off-chip interconnects, such as RF-interconnects or optical interconnect, which can be customized to specific applications or even specific phases of a given application; and 3) adaptive on-chip memory resources that help maximize data reuse for the power-efficient compute engines.
Flexibility is crucial for two reasons: first, in order for customization to be effective, our design must be adaptable to the specific needs of the application; second, prior work shows that no single architecture is best at adapting to all situations. For example, FPGAs excel in situations where there is considerable bit-level parallelism to exploit and in fixed-point bit-width optimized designs. As a further example, massively parallel engines like GPUs can readily provide high parallelism for applications using a SIMD approach, they do not perform as well for other types of parallelism, and can suffer from communication latency, particularly with respect to synchronization.
The main challenge for this Thrust is to develop a practical and implementable methodology for creating a CHP with degrees of flexibility in both its components and interconnect that are specifically tuned to a given application domain or a set of domains. CHP creation is guided by domain-specific modeling, which provides us with a variety of statically and dynamically profiled data characterizing the domain. This data guides the CHP creation phase in developing a CHP with resources and instructions customized to the needs of the domain. As any customization comes with a cost, we aim to provide only the custom resources and instructions that will be of use to the domain. Tunable resources and custom instructions will be leveraged by the compiler and runtime environment. CHP creation stage considers constraints on silicon area (determined by the cost consideration), performance (imposed by the application domain), and power (based in part on packaging and cooling constraints), as well as a library of architecture component models specific to the desired technology in which the CHP will be created.
Ultimately, CHP creation explores the best combination of cores, caches, interconnect, and other resources for the given application domain, implementing both the desired tunable ranges and custom instructions from domain-specific modeling. These will enable the efficient mapping of an application instance to a given CHP architecture so that the software layer can orchestrate these heterogeneous components and their interconnect with maximal flexibility.
Simulation Infrastructure: PARADE
To better evaluate CHP designs, we have developed our own simulation infrastructure called PARADE: the Platform for Accelerator-Rich Architectural Design and Exploration. The PARADE infrastructure is based on accelerator-rich design, with accelerators as the major building blocks of the simulator. The major components of the PARADE infrastructure are shown below:
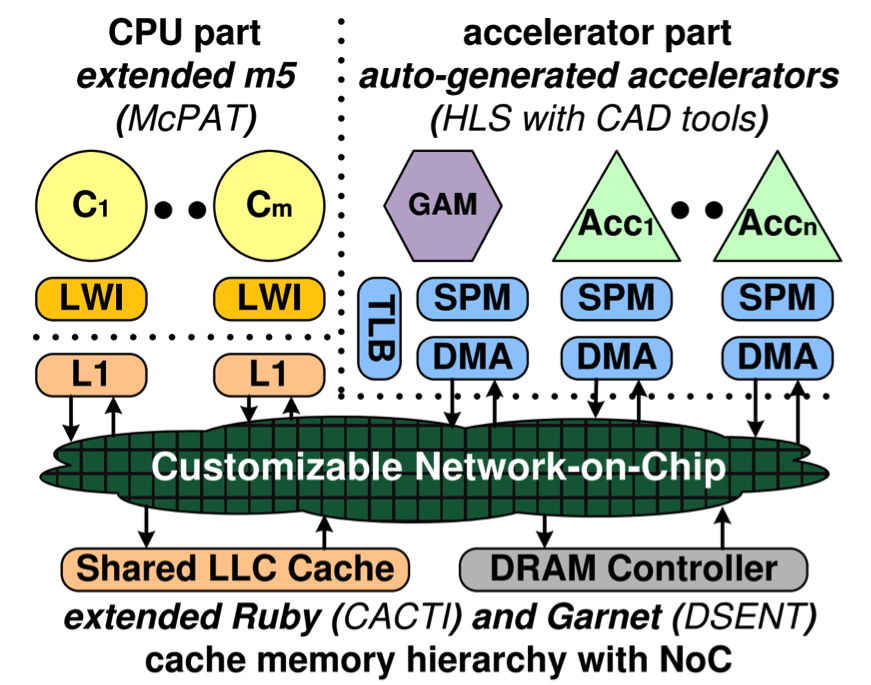
Our infrastructure models each accelerator quickly by leveraging high-level synthesis tools. In addition, we provide a flow to automatically generate either dedicated or composable accelerator simulation modules that can be integrated into PARADE. We also provide a cycle-accurate model of the hardware global accelerator manager (GAM) that efficiently manages accelerator resources in the accelerator-rich design.
Our accelerator modeling infrastructure is combined with the widely used cycle-accurate full-system simulator Gem5. With gem5, we model the CPU and cache memory hierarchy. We also provide a cycle-accurate model of the coherent cache/scratchpad with shared memory between accelerators and CPU cores, as well as a customizable network-on-chip.
In addition to performance simulation, PARADE also models the power, energy and area using existing toolchains including McPAT for the CPU, and HLS and RTL tools for accelerators. We also add visualization support to assist architects with design space exploration.
PARADE is open source and hosted at: http://vast.cs.ucla.edu/software/parade-ara-simulator
- [ICCAD15C] Jason Cong, Zhenman Fang, Michael Gill, and Glenn Reinman. PARADE: A Cycle-Accurate Full System Simulation Platform for Accelerator-Rich Architectural Design and Exploration. The 2015 IEEE/ACM International Conference on Computer-Aided Design (ICCAD 2015), Austin, Texas, November 2015.
Design Driver: Medical Imaging
Medical imaging applications often involve a pipeline of procedures: preprocessing, registration, and analysis (e.g., segmentation, feature extraction) are common steps. Each pipeline stage involves computationally intensive algorithms (each with distinct communication and processing patterns) and solutions entailing a set of (non-linear) optimizations proportional to the image size and the total number of images in a volumetric set. The amount of data requiring processing in one imaging study is dependent on several parameters, but today’s cross-sectional studies range from 200-800 MB. With the rapid evolution of scanners, the amount of imaging data gathered is only expected to grow, though the size of future image datasets will likely have no difficulty fitting into the main memory of current and next-generation systems (avoiding foreseeable performance bottlenecks from I/O); however, the amount of data will outpace our ability to efficiently analyze the information.
 Power-efficiency has become one of the primary design goals in the many-core era. On-chip accelerators are application-specific implementations that provide power-efficient implementations of a particular functionality, and can range from simple tasks (i.e., a multiply accumulate operation) to tasks of more moderate complexity (i.e., an FFT or DCT) to even more complex tasks (i.e., complex encryption/ decryption or video encoding/decoding algorithms).
Power-efficiency has become one of the primary design goals in the many-core era. On-chip accelerators are application-specific implementations that provide power-efficient implementations of a particular functionality, and can range from simple tasks (i.e., a multiply accumulate operation) to tasks of more moderate complexity (i.e., an FFT or DCT) to even more complex tasks (i.e., complex encryption/ decryption or video encoding/decoding algorithms).
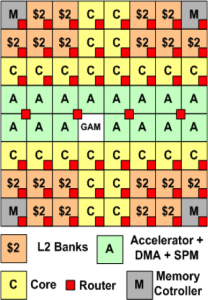
We proposed ARC, an Accelerator-Rich CMP that features a Global Accelerator Manager (GAM). The GAM is a hardware resource manager for accelerator sharing supporting sharing and arbitration of multiple cores for a common set of accelerators. It uses a hardware-based arbitration mechanism to provide feedback to cores to indicate the wait time before a particular resource becomes available and light-weight interrupts to reduce the OS overhead. A single accelerator instance can provide an average 36X performance over software running on a 4-core Xeon E5405 @ 2.0GHz.
- [DAC12C] J. Cong, M.A. Ghodrat, M. Gill, B. Grigorian, and G. Reinman. Architecture support for accelerator-rich CMPs. Proceedings of the 49th Annual Design Automation Conference (DAC). June 2012.
Composable Heterogeneous Accelerator-Rich Microprocessor (CHARM)
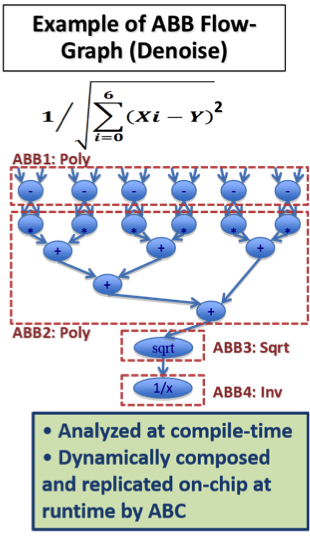
Accelerators are inflexible, which not only limits their use for new algorithms/domains but can also be underutilized and area-inefficient due to replicated structures across different accelerators. To address these concerns, we proposed CHARM, a Composable Heterogeneous Accelerator-Rich Microprocessor design that provides scalability, flexibility, and design reuse in the space of accelerator-rich CMPs. CHARM features a hardware structure called the accelerator block composer (ABC), which can dynamically compose a set of accelerator building blocks (ABBs) into a loosely coupled accelerator (LCA) to provide orders of magnitude improvement in performance and power efficiency. Our software infrastructureprovides a data flow graph to describe the composition, and our hardware components dynamically map available resources to the data flow graph to compose the accelerator from components that may be physically distributed across the CMP. Our ABC is also capable of providing load balancing among available compute resources to increase accelerator utilization.
- [ISLPED12C] J. Cong, M.A. Ghodrat, M. Gill, B. Grigorian and G. Reinman. CHARM: A Composable Heterogeneous Accelerator-Rich Microprocessor. Proceedings of the International Symposium on Low Power Electronics and Design (ISLPED 2012), Redondo, California, pp. 379-384, July-August 2012
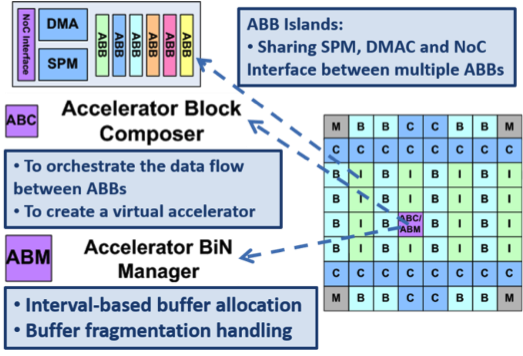
Composable Accelerator-rich Microprocessor Enhanced for Adaptivity and Longevity (CAMEL)
While CHARM is able to provide more flexibility than monolithic accelerator architectures, the various ABBs used to compose accelerators in CHARM are still fixed at design time for a particular CHP. CHARM and other accelerator-rich platforms lack adaptivity to new algorithms and can see low accelerator utilization. To address these issues we propose CAMEL: Composable Accelerator-rich Microprocessor Enhanced for Longevity. CAMEL features programmable fabric (PF) to extend the use of ASIC composable accelerators in supporting algorithms that are beyond the scope of the baseline platform.
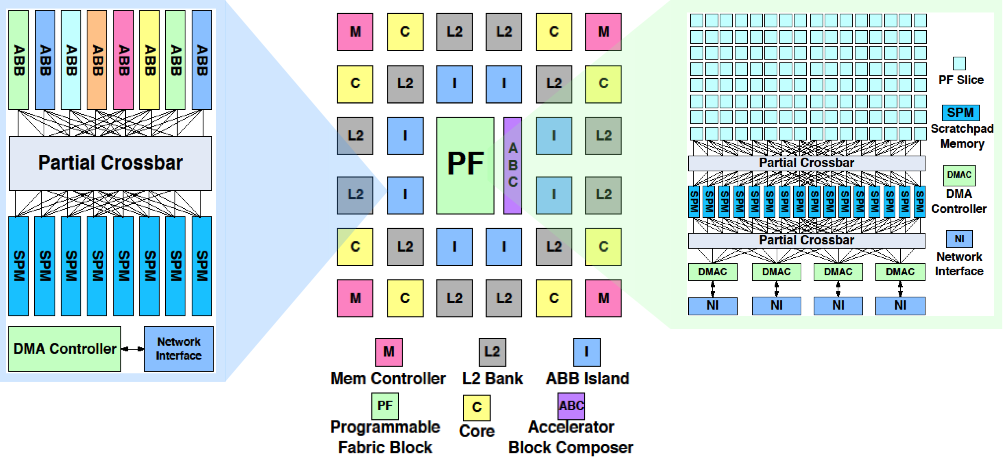
The figure above demonstrates the CAMEL CHP, where ABB islands (blue I’s) are distributed across the chip and may be composed together and with the green programmable fabric (PF) to form accelerators. The results below show how well a set of ABBs that were designed for one domain (medical imaging) perform when combined with different amounts of programmable fabric (shown along the x-axis) for different domains (Vision, Navigation, and Commercial domains). Programmable fabric provides the flexibility for the composable approach to adapt to new domains and algorithms.
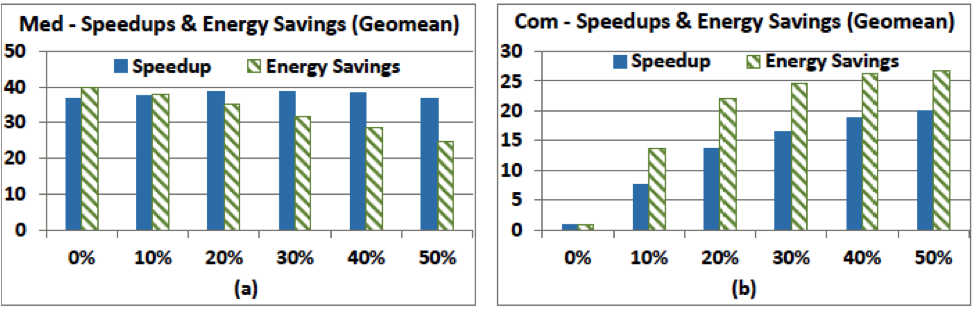
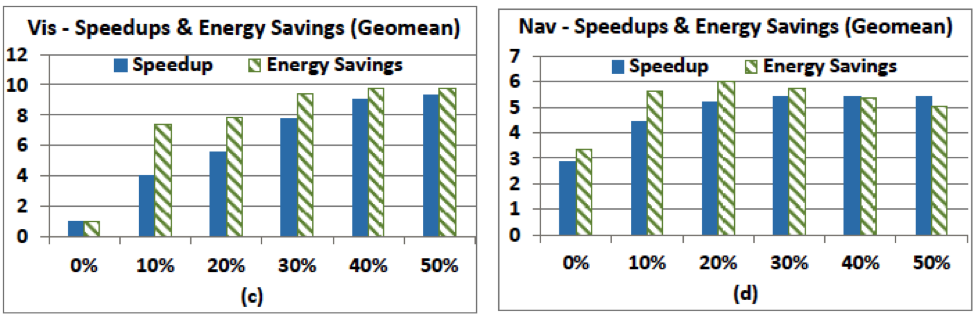
- [ISLPED13C] J. Cong, M.A. Ghodrat, M. Gill, B. Grigorian, H. Huang and G. Reinman. Composable Accelerator-rich Microprocessor Enhanced for Adaptivity and Longevity. Proceedings of the International Symposium on Low Power Electronics and Design (ISLPED 2013), pp. 305-310, September 2013.
As the number of on-chip accelerators grows rapidly to improve power-efficiency, the buffer size required by accelerators drastically increases. Existing solutions allow the accelerators to share a common pool of buffers or/and allocate buffers in cache. But no prior work considers global buffer allocation among multiple accelerators, where each has a range of buffer size requirements with different buffer utilization efficiencies. Moreover, no prior work considers the space fragmentation problem in a shared buffer, especially when allocating buffers in a non-uniform cache architecture (NUCA) with distributed cache banks. In this paper we propose a Buffer-in-NUCA (BiN) scheme with the following contributions: (1) a dynamic interval-based global allocation method to assign spaces to accelerators that can best utilize the additional buffer space, and (2) a flexible paged allocation method to limit the impact of buffer fragmentation, with only a small local page table at each accelerator. Experimental results show that, when compared to two representative schemes from the prior work, BiN improves performance by 32% and 35% and reduces energy by 12% and 29%, respectively.
- [ISLPED12C] J. Cong, M.A. Ghodrat, M. Gill, C. Liu and G. Reinman. BiN: A Buffer-in-NUCA Scheme for Accelerator-Rich CMPs. International Symposium on Low Power Electronics and Design (ISLPED), Jul/Aug 2012.
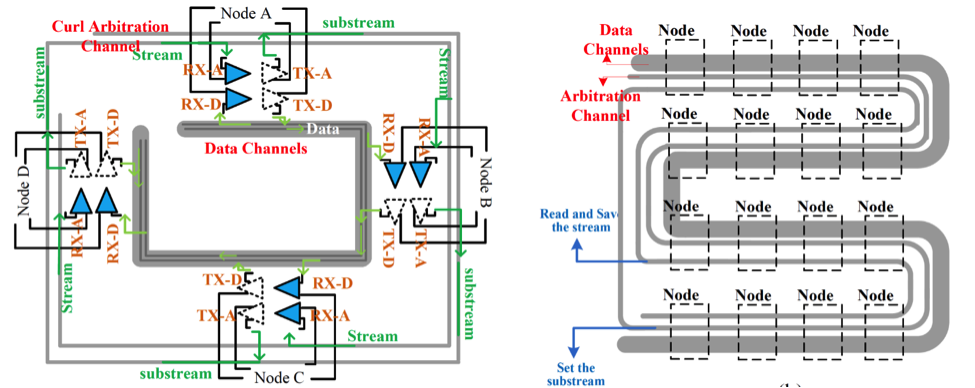
Alternative interconnects are attractive for scaling on-chip communication bandwidth in a power-efficient manner. However, efficient utilization of the bandwidth provided by these emerging interconnects still remains an open problem due to the spatial and temporal communication heterogeneity. We propose a Stream Arbitration scheme, where at runtime any source can compete for any communication channel of the interconnect to talk to any destination. We apply stream arbitration to radio frequency interconnect (RF-I). Experimental results show that compared to the representative token arbitration scheme, stream arbitration can provide an average 20% performance improvement and 12% power reduction. Below is one example of an NoC architecture using Stream Arbitration, with an RF-I transmission line (light blue) spanning the various components on the chip.
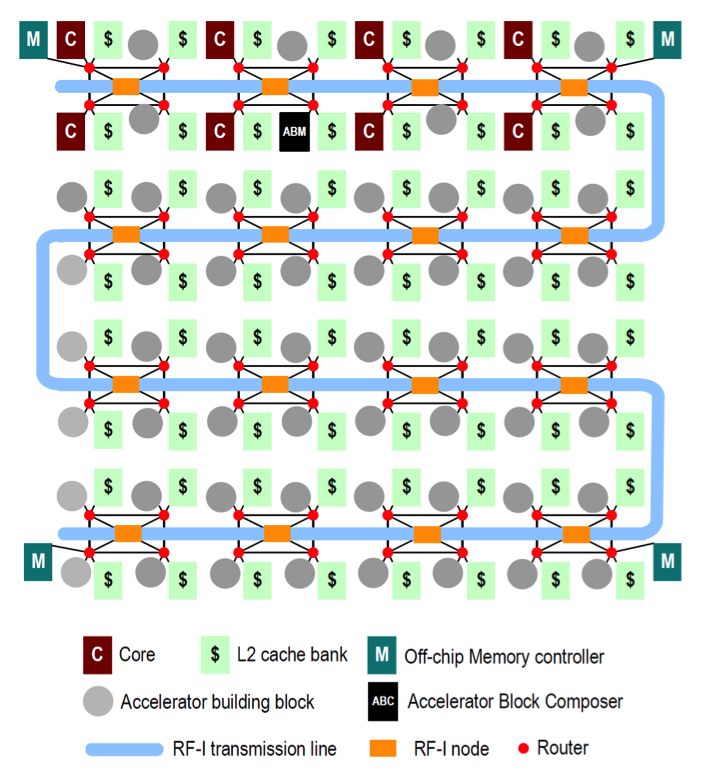
Stream Arbitration leverages an arbitration channel separate from the data channels of the RF-I. The key component of our approach is the arbitration stream that travels across the arbitration channel. Conceptually, the arbitration stream starts at a single node, which is called the stream origin. The arbitration stream starts out logically empty and will travel in a unidirectional manner across all the nodes on the chip; this is called Trip 1. In this trip, when the stream passes each node, the node logically augments a number of bits (referred to as substream) in the arbitration stream to specify whether or not this node is attempting to send to another node, and whether or not this node is capable of receiving packets. It is important to note that these two pieces of information (desire to send and availability to receive) do not require any parsing of the stream—they only rely on information known a priori at the node. So there is no dependence where the stream must be read first and then modified. Such a dependence would impact arbitration latency by bringing slow logic on the critical path of the stream propagation.
After the arbitration stream passes the last RF node in Trip 1, it circulates over all nodes a second time, which we refer to as Trip 2. In this trip, when the stream passes each node, the node receives the arbitration stream but does not modify the stream. The purpose of Trip 2 is to parse the stream in order to determine whether each node has the ability to send and to what channel each node should listen in the subsequent data transmission.
After the arbitration stream is parsed, the transmitter of a source node that has successfully acquired a data channel will be tuned to send on this channel, and the receiver of the intended destination node will be tuned to listen to the same data channel. A node can be a source and a destination simultaneously, using different channels. After Trip 2, the sources that successfully acquired data channels begin to use these data channels to communicate with their corresponding destinations. A channel is used for a single flit, and is surrendered after the flit transmitted. This does not incur a performance penalty because arbitration can be initiated every cycle, so a pair of nodes is allowed to communicate so long as the source continues to win arbitration. This requires stream arbitration and data transferring to be pipelined.
Below, the transmission line interface (left) and arbitration and data channel layout (right) is shown.
- [TACO13X] C. Xiao, M. F. Chang, J. Cong, M. Gill, Z. Huang, C. Liu, G. Reinman, H. Wu. Stream arbitration: Towards efficient bandwidth utilization for emerging on-chip interconnects. ACM Transactions on Architecture and Code Optimization (TACO), Jan 2013.
Interconnection Networks for Accelerator-Rich Architectures
Hardware accelerators provide high computation capability and low energy consumption. However, hardware accelerators cannot tolerate memory and communication latency through extensive multithreading; this increases the demand for efficient memory interface and network-on-chip (NoC) designs. The NoC has considerable impact on overall system performance. Much past research has addressed NoC in homogeneous multi-core processers, lowering network latency and congestions. However, as hardware accelerators become ubiquitous in modern processors, it is necessary to examine NoC performance in the context of accelerator-rich architectures.
The throughput of an accelerator is often bound by the rate at which the accelerator is able to interact with the memory system. Existing interconnect designs for accelerator architectures use partial crossbar switches, bus and packet-switched networks to transfer data between memory and accelerators. But accelerator memory accesses exhibit predictable patterns, creating highly utilized network paths.
Leveraging this observation, we propose the Hybrid network with Predictive Reservation (HPR). By introducing circuit-switching to cover accelerator memory accesses, HPR reduces per-hop delays for accelerator traffic. Unlike previous circuit-switching proposals, HPR eliminates circuit-switching setup and teardown latency by reserving circuit-switched paths when accelerators are invoked. We use a hybrid switched router architecture as shown below. We further maximize the benefit of paths reservation by regularizing the communication traffic through TLB buffering and hybrid-switching.
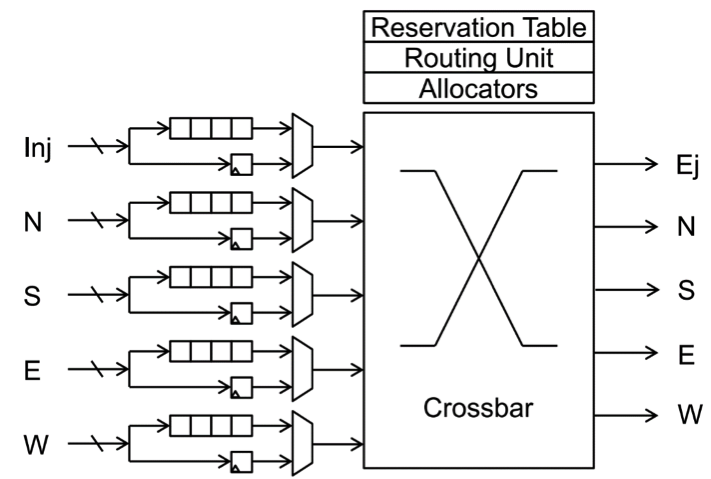
The combined effect of these optimizations reduces the total execution time by 11.3% over a packet-switched mesh NoC.
- [DAC15C] Jason Cong, Michael Gill, Yuchen Hao, Glenn Reinman, and Bo Yuan. On-chip Interconnection Network for Accelerator-Rich Architectures. Design Automation Conference (DAC) 2015, San Francisco, CA, June 7-11, 2015.