
Goals
- Prototype the novel architecture ideas and components in the proposed customizable heterogeneous platform (CHP) at chip-level, server-node level, and cluster/datacenter level.
- Validate and demonstrate the advantages of new emerging technologies, such as RF-interconnect and memristor arrays
People
- Thrust Leader: Jason Cong (UCLA)
- Faculty: Frank Chang, Glenn Reinman (UCLA), Tim Cheng (UCSB)
- Postdoc/Research Staff: Zhenman Fang, Mohammadali Ghodrat, Po-Tsang Huang, SheauJiung Lee, Jie Lei (UCLA)
- Students:
- UCLA: Yu-Ting Chen, Wei-Han Cho, Young-kyu Choi, Yuan Du, Michael Gill, Beayna Grigorian, Hui Huang, Muhuan Huang, Yanghyo Kim, Sen Li, Yilei Li, Chunyue Liu, Lan Nan, Sai-Wang Tam, Yi-Chu Wang, Peng Wei, Di Wu, Hao Wu, Bingjun Xiao, Ming Yan, Peipei Zhou, Yi Zou
- UCSB: Amirali Ghofrani, Miguel Angel Lastras-Montaño
Focused Areas:
Chip-Level Prototyping, Sever-Node Level Prototyping, Cluster/Datacenter Level Prototyping, RF-interconnect, Memristor-based Technologies,
Prototyping Systems for Customized Computing
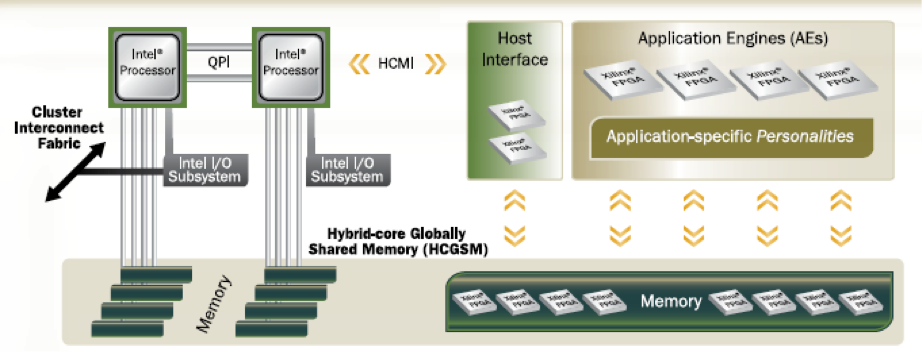
CHARM (Composable Heterogeneous Accelerator-Rich Microprocessor) provides scalability, flexibility, and design reuse in the space of accelerator-rich CMPs. It features a hardware structure called the accelerator block composer (ABC), which can dynamically compose a set of accelerator building blocks (ABBs) into a loosely coupled accelerator (LCA) to provide orders of magnitude improvement in performance and power efficiency. Our software infrastructure provides a data flow graph to describe the composition, and our hardware components dynamically map available resources to the data flow graph to compose the accelerator from components that may be physically distributed across the CMP. ABC is also capable of providing load balancing among available compute resources to increase accelerator utilization.
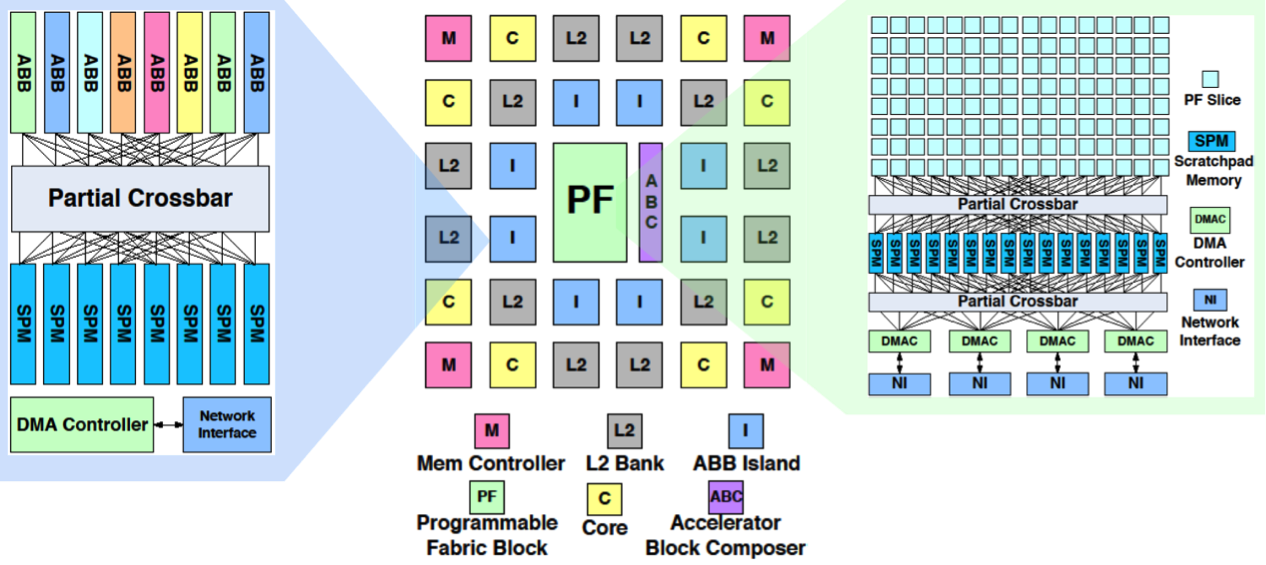
Prototype has been implemented in Xilinx Virtex-6 FPGA. We name it as Fully Pipelined and dynamically Composable CGRA Architecture (FPCA). FPCA has two novel features:
- Full Pipelining of innermost loop for maximum throughput
- Dynamic composition of accelerator
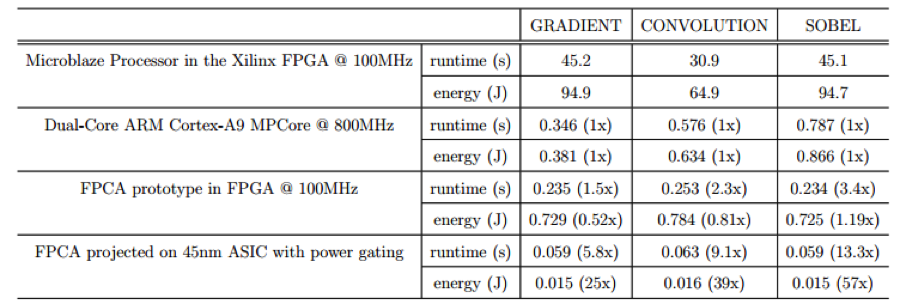
Experiments show that our architecture can achieve a >50x energy savings due to customization for user applications with rich transistor resources.
The average composition time for three application kernels is 0.355ms. Bit-stream download time in FPGA on average is more than 10s. Compared to FPGA, our FPCA saves time in the reconfiguration process.
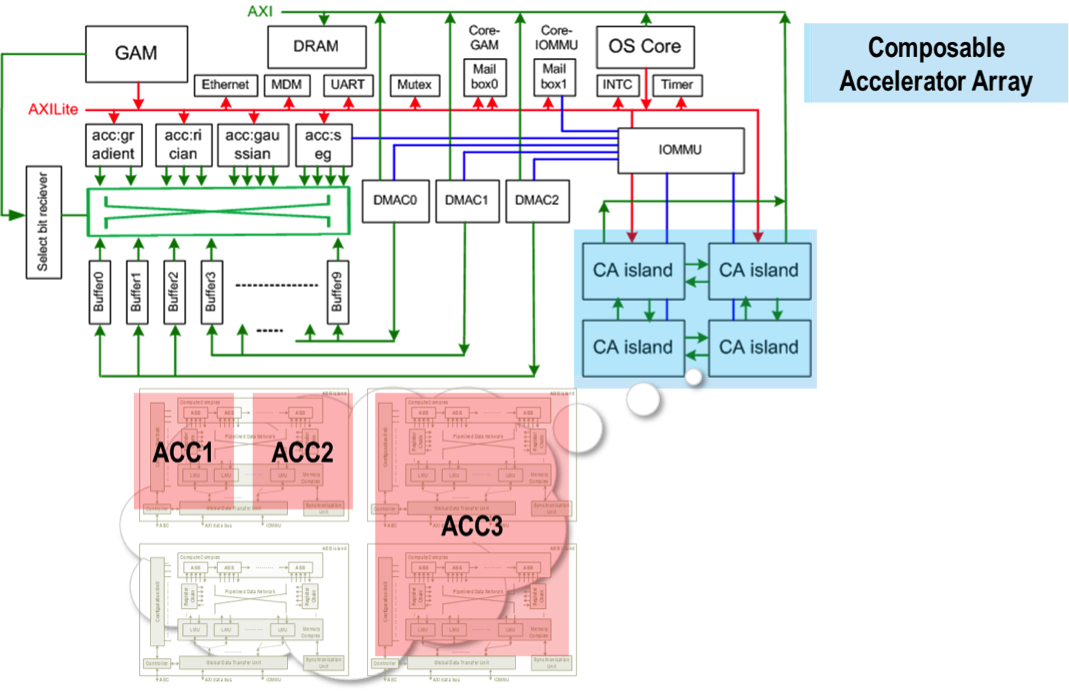
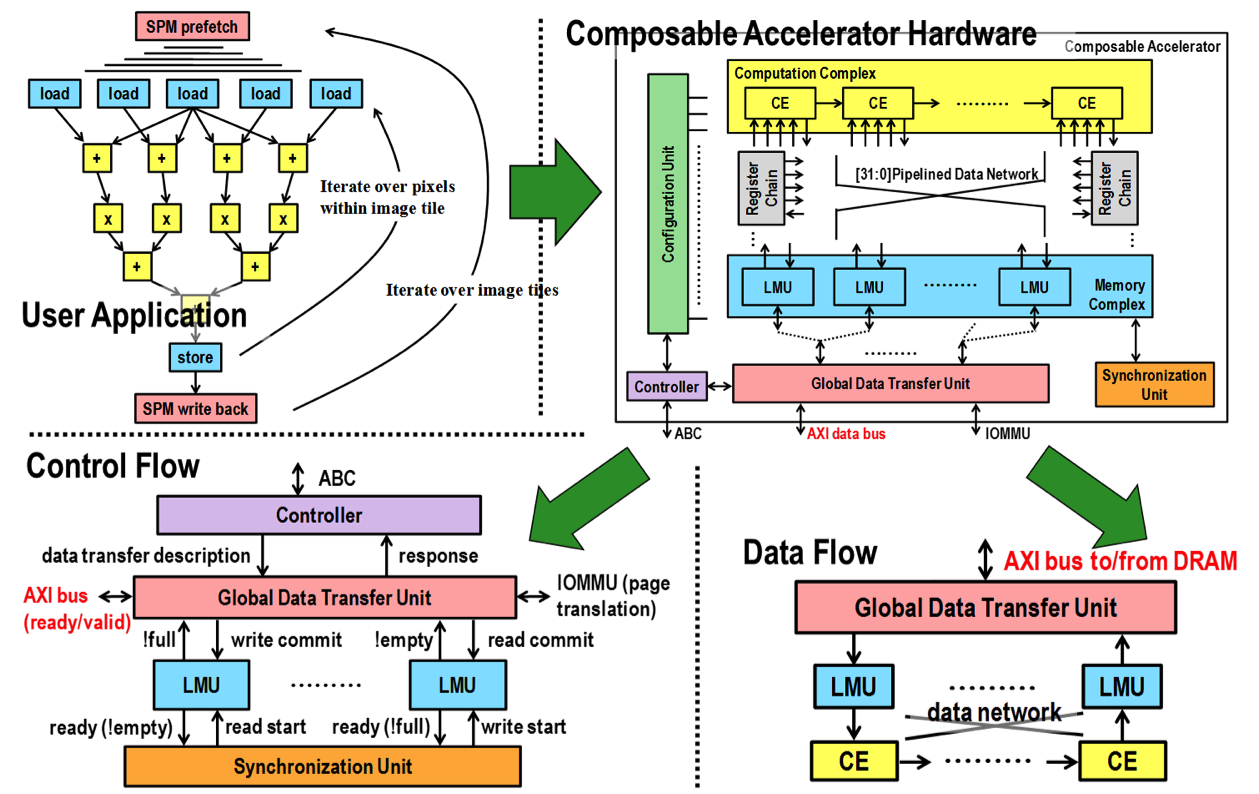
- [ISLPED12C] Cong, M.A. Ghodrat, M. Gill, B. Grigorian and G. Reinman. CHARM: A Composable Heterogeneous Accelerator-Rich Microprocessor. Proceedings of the International Symposium on Low Power Electronics and Design (ISLPED 2012), Redondo, California, pp. 379-384, July-August 2012.
- [ISLPED12C] Cong, M.A. Ghodrat, M. Gill, C. Liu and G. Reinman. BiN: A Buffer-in-NUCA Scheme for Accelerator-Rich CMPs . Proceedings of the International Symposium on Low Power Electronics and Design (ISLPED 2012), Redondo, California, pp. 225-230, July-August 2012.
- [ICCD12C] Yu-Ting Chen, Jason Cong, Mohammad Ali Ghodrat, Muhuan Huang, Chunyue Liu, Bingjun Xiao, Yi Zou. Accelerator-rich CMPs: From concept to real hardware. International Conference on Computer Design (ICCD) 2013.
- [ISLPED13C] Cong, M.A. Ghodrat, M. Gill, B. Grigorian, H. Huang and G. Reinman. Composable Accelerator-rich Microprocessor Enhanced for Adaptivity and Longevity. Proceedings of the International Symposium on Low Power Electronics and Design (ISLPED 2013), pp. 305-310, September 2013.
- [FCCM14C] Cong, H. Huang, C. Ma, B. Xiao and P. Zhou. A Fully Pipelined and Dynamically Composable Architecture of CGRA. Proceedings of the 22nd IEEE International Symposium on Field-Programmable Custom Computing Machines (FCCM), Boston, Massachusetts, May 2014.
We have developed a pipeline of medical image processing on Convey server class platforms. The pipeline is composed of reconstruction, denoising, registration, segmentation and analysis. We heavily parallelized the computation to reduce the computation time. We also used target-specific optimizations such as pipelining and fixed-point arithmetic for FPGAs. We also developed an efficient reuse scheme by transferring data into the internal memory (shared memory in GPU and block RAM in FPGA). The overall execution time has around 19 hours, with EM+TV algorithm that we used for 3D CT image reconstruction having the longest running time of 18 hours. It was reduced to about 30 minutes. The goal of this task is to reduce the runtime to 2 to 3 minutes through customized heterogeneous computing using GPUs and FPGAs.

- [FTDIRRNM11C] J. Chen, M. Yan, L.A. Vese, J. Villasenor, A. Bui and J. Cong. EM+TV for Reconstruction of Cone-Beam CT with Curved Detectors Using GPU. Proceedings of International Meeting on Fully Three-Dimensional Image Reconstruction in Radiology and Nuclear Medicine, Potsdam, Germany, pp. 363-366, July 2011.
- [FPGA12C] J. Chen, J. Cong, M. Yan and Y. Zou. FPGA-Accelerated 3D Reconstruction using Compressive Sensing . Proceedings of the 20th ACM/SIGDA International Symposium on Field-Programmable Gate Arrays (FPGA 2012), Monterey, CA, pp. 163-166, February 2012.
- [JESTS12C] J. Chen, J. Cong, L.A. Vese, J. Villasensor, M. Yan and Y. Zou. A Hybrid Architecture for Compressive Sensing 3-D CT Reconstruction. IEEE Journal on Emerging and Selected Topics in Circuits and Systems, Volume 2, Issue 3, pp. 616-625, September 2012.
- [FCCM14C] Y. Choi, J. Cong, and D. Wu. FPGA Implementation of EM Algorithm for 3D CT Reconstruction. Proceedings of the 22nd IEEE International Symposium on Field-Programmable Custom Computing Machines (FCCM), Boston, Massachusetts, May 2014.
- [TBCS15C] Young-kyu Choi and Jason Cong, “Acceleration of EM-Based 3D CT Reconstruction Using FPGA,” accepted for publication in IEEE Transactions at Biomedical Circuits and Systems, 2015.
Cluster/Datacenter Level Prototyping
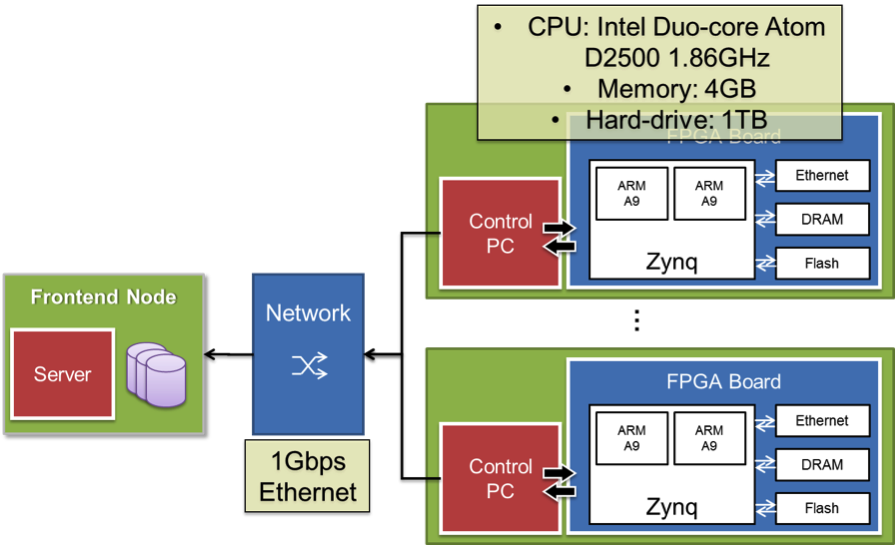
FARM: FPGA-based Accelerator-Rich Mini-cluster. The Farm is a low-power, multi-node cluster of FPGA computing devices. It was initially built for the class project of CS133 (Parallel and Distributed Computing) in UCLA, taught by Professor Jason Cong. It is also used in research projects on heterogeneous resource management and large-scale energy-efficient computation.
In the Farm, there are one front-end server and six computation nodes. All machines are connected to a local network, and only the front-end node is visible to the public network. Each computation node consists of one Intel Atom PC and one FPGA board.
- Front-end server: The front-end server manages DHCP, TFTP and NFS services for the entire Farm. In the current setup, the front-end node is also used in computation and software compilation.
- Atom PC: The Atom PC is used as control for the FPGA board. It can reset the FPGA board and start debugging session using JTAG and UART interface.
- FPGA: The FPGA boards can serve as computation nodes directly connected to the network, or as accelerator slaves of the computation nodes.


[ASPDAC12B] A. Bui, K. Cheng, J. Cong, L. Vese, Y. Wang, B. Yuan and Y. Zou. Platform Characterization for Domain-Specific Computing. Proceedings of the 17th Asia and South Pacific Design Automation Conference (ASPDAC 2012), Sydney, Australia, pp. 94-99, January 2012 (Invited paper).
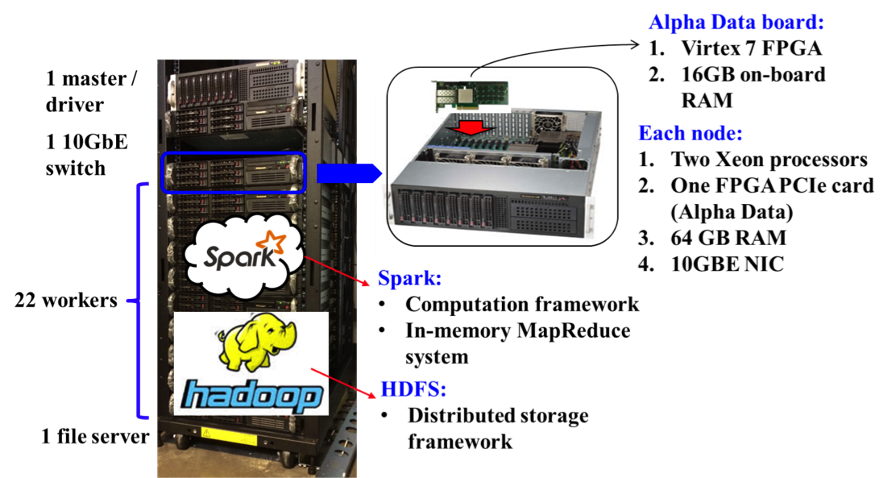
CDSC cluster. We built our 25-node CDSC cluster to explore the possibility of providing customized acceleration at the datacenter scale. We deployed Spark and Hadoop distributed file systems (HDFS) as the computation and storage infrastructures, respectively. Each node has a PCIe-based FPGA card for realizing customized accelerators.
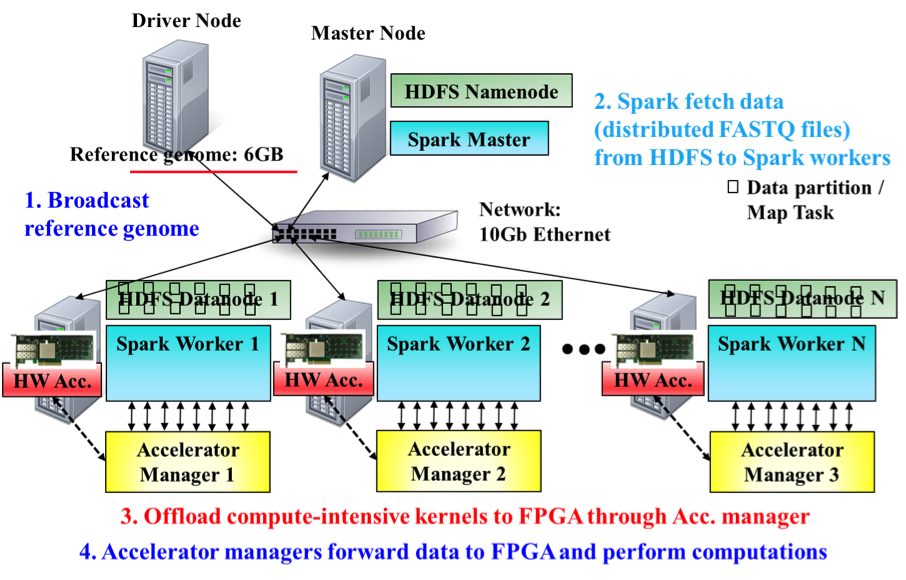
Currently we mainly focused on using our CDSC cluster to accelerate the genomics DNA sequencing pipeline. The deep-coverage whole-genome sequencing (WGS) can generate billions of reads to be sequenced. We developed cloud-scale BWAMEM (CS-BWAMEM), an ultrafast and highly scalable aligner built on top of our CDSC cluster. It leverages the abundant computing resources in a public or private cloud to fully exploit the parallelism obtained from the enormous number of reads.
To further scale up the performance inside one node, we designed PCIe-based FPGA accelerators to accelerate the compute-intensive kernels. We also developed the accelerator manager that takes the requests and input data from CS-BWAMEM and offloads computation to the accelerators.
[HiTSEQ15C] Yu-Ting Chen, Jason Cong, Sen Li, Myron Peto, Paul Spellman, Peng Wei, and Peipei Zhou. CS-BWAMEM: A fast and scalable read aligner at the cloud scale for whole genome sequencing. High Throughput Sequencing Algorithms and Applications (HiTSEQ) Poster Session Dublin, Ireland, July 2015. Best Poster Award (2/70).
[FCCM15C] Yu-Ting Chen, Jason Cong, Jie Lei, and Peng Wei. A Novel High-Throughput Acceleration Engine for Read Alignment. The 23rd Annual IEEE International Symposium on Field-Programmable Custom Computing Machines (FCCM ’15), Vancouver, British Columbia, Canada, May 2015.
[DAC16C1] Young-kyu Choi, Jason Cong, Zhenman Fang, Yuchen Hao, Glenn Reinman, and Peng Wei. A Quantitative Analysis on Microarchitectures of Modern CPU-FPGA Platforms. To appear in the 53rd Design Automation Conference (DAC 2016), 2016.
[DAC16C2] Jason Cong, Muhuan Huang, Di Wu, and Cody Hao Yu. Heterogeneous Datacenters: Options and Opportunities. To appear in the 53rd Design Automation Conference (DAC 2016), 2016.
[HotCloud16C] Yu-Ting Chen, Jason Cong, Zhenman Fang, Jie Lei, and Peng Wei. When Spark Meets FPGA: A Case Study for Next-Generation DNA Sequencing Acceleration. To appear in the 8th USENIX Workshop on Hot Topics in Cloud Computing (HotCloud 16), 2016.
Prototyping Systems for Emerging Technologies
In order to scale future CMPs to 100’s or even 1000’s of cores, sophisticated interconnect topologies will be essential in enabling low-latency application communication and efficient cache utilization. We find that RF interconnects have tremendous promise in providing higher bandwidth between such a large number of interacting components, as well as reducing the number of cycles required for cross-chip communication, via signal propagation at the speed of light. It can be achieved by selectively allocating RF-I bandwidth between different components on-chip. Multiple bandwidth channels can coexist on the shared RF-I waveguide for simultaneous communication.
The below diagram shows the five-band RF-interconnect with QPSK demodulation.
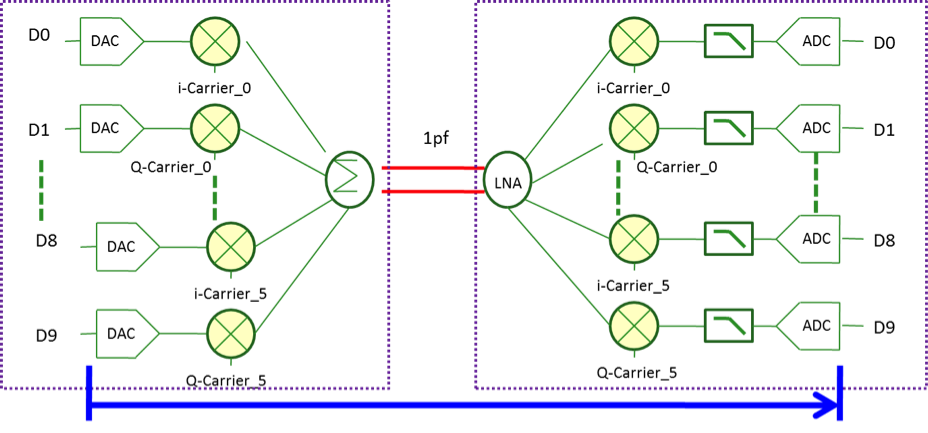
The performance comparison is shown below. It has been tested on 40nm, and has end-to-end (DAC to ADC) delay measured <2.5 ns at all data rates. This latency is much superior to DDR3/4 (>15 ns) or wide I/O (>7 ns). Also, it has 3X – 12X improvement on energy per bit.

We have developed a 5Gbps on-chip multi-drop bus using RF-Interconnect with arbitrary broadcast and destructive reading functions. We successfully realized a 5Gbps bi-directional RF-Interconnect (RF-I) with multi-drop and arbitration capabilities in 65nm CMOS. We have also realized a dual-band RF-Interconnect for Memory-I/O with a single-ended transmission line. We demonstrated a dual-band interconnect on an off-chip printed circuit board for high-bandwidth mobile memory interface applications.
- [ISPD08C] M.-C. F. Chang, E. Socher, S.-W. Tam, J. Cong, and G. Reinman. Rf interconnects for communications on-chip. In Proceedings of the 2008 international symposium on Physical design, ISPD ’08, pages 78–83, New York, NY, USA, 2008.
- [SLIP09C] J. Cong, M. F. Chang, G. Reinman, and S.-W. Tam. Multiband RF-Interconnect for Reconfigurable Network-on-Chip Communication . System Level Interconnect Prediction (SLIP 2009), San Francisco California, pp. 107-108, July 2009.
- [MobiCom09L] S-B. Lee, S.-W. Tam, I. Pefkianakis, S. Lu, M. F. Chang, C. Guo, G. Reinman, C. Peng, M. Naik, L. Zhang, and J. Cong. A Scalable Micro Wireless Interconnect Structure for CMPs . ACM MobiCom 2009, Beijing, China, pp. 217-228, September 2009.
- [CICC12W] H. Wu, L. Nan, S.-W. Tam, H.-H. Hsieh, C. Jou, G. Reinman, J. Cong, and M.-C. F. Chang. A 60GHz On-Chip RF-Interconnect with λ/4 Coupler for 5Gbps Bi-Directional Communication and Multi-Drop Arbitration. Proceedings of IEEE Custom Integrated Circuits Conference (CICC 2012), San Jose, California, September 2012.
- [CICC15C] W.-H. Cho, Yilei Li, Yanghyo Kim, Po-Tsang Huang, Yuan Du, SheauJiung Lee,and Mau-Chung Frank Chang, “A 5.4-mW 4-Gb/s 5-Band QPSK transceiver for frequency-division multiplexing memory interface”, to appear in CICC Dig. Tech. Papers, Sept. 2015.
First prototype of 3D memristive RAM with monolithic integration of CMOS and multi-layer memristive crossbar arrays with an area-distributed interface is shown below. We proposed an adaptive write scheme with 10X average energy saving for the write operation. It addresses the data reliability issues for 3D memristive RAM. It also demonstrates implementation of energy-efficient TCAM using memristive crossbars supporting GPGPU. We also developed a new hybrid reconfigurable resistive random access memory, named HReRAM. HReRAM intelligently combines the strengths of the complementary resistive switch (CRS) with the existing memristive switch to form a hybrid reconfigurable resistive RAM for achieving optimized endurance and energy consumption while alleviating the “sneak-path” problems of memristive crossbar arrays.
- [NANOARCH11C] Cong and B. Xiao. mrFPGA: A Novel FPGA Architecture with Memristor-Based Reconfiguration. Proceedings of the 7th IEEE/ACM International Symposium on Nanoscale Architectures (NANOARCH 2011), San Diego, CA, pp. 1-8, June 2011.
- [DATE15R] Rahimi, A. Ghofrani, A., K.–T, Cheng, L. Benini, and R. K. Gupta, “Approximate Associative Memristive Memory for Energy-Efficient GPUs”, Design, Automation Test in Europe Conference Exhibition (DATE), March 2015.
- [NANOARCH15L] A. Lastras-Montano, A. Ghofrani, and K.-T. Cheng, “Architecting Energy Efficient Crossbar-based Memristive Random Access Memories”, in ACM/IEEE International Symposium on Nano-scale Architectures (NANOARCH’15), July 2015.
- [DATE15L] A. Lastras-Montano, A. Ghofrani, and K.-T. Cheng, “HReRAM: A Hybrid Reconfigurable Resistive Random-Access Memory”, Design, Automation, and Test in Europe (DATE), March 2015.
- [ASPDAC15G] Ghofrani, M. A. Lastras-Montano, and K.-T. Cheng, “Toward Large-Scale Access-Transistor-Free Memristive Crossbars”, in 20th Asia and South Pacific Design Automation Conference (ASP-DAC), January 2015.